很多站长和开发者在使用海外服务器时,一定经历过敲一个 ls 命令都要卡顿两三秒;更别提一到晚高峰,代码还没传完,终端直接给你报一个 Connection closed。
明明买的 CPU 和内存配置也不低,为什么用起来却极其痛苦?
作为开发者,时间是最宝贵的,把精力浪费在等待服务器响应上完全是在本末倒置。这篇文章就来帮你系统地把脉,彻底揪出导致海外 VPS 变慢的“真凶”。
一、排查系统性能与硬件瓶颈
当你在终端敲击键盘感觉极其卡顿,或者访问服务器上的网站转圈不停时,绝大多数人的第一反应是“网络太差了”。但很多时候,我们往往忽略了服务器内部的健康状况。
如果服务器自身的硬件资源已经消耗殆尽,即使给它接上全球顶级的线路,它的响应依然迟缓。因此,排查海外 VPS 变慢的原因,先看看服务器的状态是否正常。
1. 可视化面板排查(以 1Panel 为例)
如果服务器上部署了 1Panel 这种现代化、可视化的 Linux 面板,那么排查内部瓶颈会变得非常直观。登录 1Panel 面板后,首先将目光聚焦在首页的“系统状态”仪表盘上。
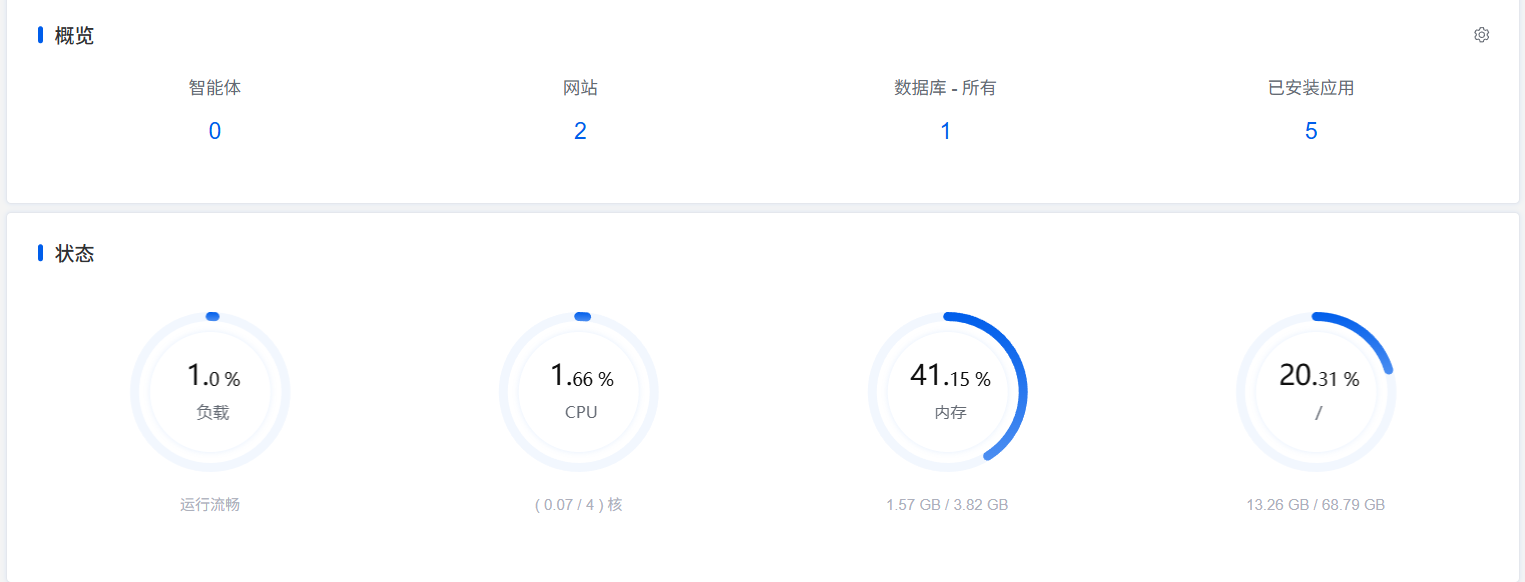
在查看面板数据时,需要特别盯紧以下三个核心指标:
- 负载(Load Average): 很多人误以为 CPU 使用率只要没到 100% 就没事,其实一个健康的状态应该维持在 60% 左右,如果高于 80% 就该升级配置了。
- 内存使用率: 留意内存是否已经逼近 90% 以上。海外 VPS 往往配置有限(例如常见的 1核1G 或 1核2G),如果同时运行了数据库、Web 服务,内存很容易见底。
- 磁盘 I/O 读写状态: 某些廉价海外 VPS 的母机超售严重,或者严格限制了硬盘读写速度(IOPS)。如果 I/O 等待时间过长,整个系统就会陷入严重的阻塞状态。
💡 实战场景分析:
如果发现 CPU 和磁盘 I/O 同时拉满,最常见的原因有:一是数据库(如 MySQL)由于缺乏索引或遭遇高并发;二是网站可能正遭遇恶意的蜘蛛大量扫盘、撞库攻击或遭遇突发的恶意流量。
此时,系统的所有底层资源都被用于应对这些并发请求,留给系统远程管理的资源所剩无几,SSH 终端卡死也就不足为奇了。
2. 原生 Linux 命令行排查(硬核党必备)
如果由于网络极度卡顿,甚至连 1Panel 面板都无法顺利打开,或者更习惯使用纯净的 Linux 命令行环境,可以直接通过 SSH 终端,使用原生命令来给服务器做一次快速体检。
① 终端性能风向标:top 或 htop 命令
在终端输入并回车执行 top 命令(如果系统安装了 htop,强烈推荐使用交互感更好的 htop):
# 执行 top 命令
top - 10:38:32 up 17 days, 20:01, 1 user, load average: 0.28, 0.14, 0.10
Tasks: 178 total, 1 running, 176 sleeping, 0 stopped, 1 zombie
%Cpu(s): 1.2 us, 1.0 sy, 0.0 ni, 97.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3915.4 total, 614.7 free, 1640.5 used, 1960.3 buff/cache
MiB Swap: 1024.0 total, 1024.0 free, 0.0 used. 2274.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1511 999 20 0 2103908 461976 35328 S 1.3 11.5 199:42.65 mysqld
886 root 20 0 2873924 103612 64384 S 1.0 2.6 83:54.29 dockerd
2395 1001 20 0 30.8g 177796 55936 S 1.0 4.4 54:51.35 next-server (v
787 root 20 0 2534372 63396 35712 S 0.7 1.6 93:39.81 containerd
1858 root 20 0 636164 15484 8064 S 0.7 0.4 2:31.20 openresty
1357 root 20 0 1233840 17572 7424 S 0.3 0.4 50:53.13 containerd-shim
1916613 root 20 0 0 0 0 I 0.3 0.0 0:01.48 kworker/1:2-ev
在弹出的实时监控界面中,需要重点关注两点:
- 看最上方一行的
load average,核对前文提到的系统平均负载是否过高。 - 看下方进程列表中的
%CPU和%MEM列。按快捷键P(大写)可以按 CPU 使用率从高到低排序,按M(大写)可以按内存占用排序。
② 内存剩余容量体检:free -h 命令
如果怀疑是内存不足导致的系统卡顿,可以使用以下命令查看:
root@xxx:~# free -h
total used free shared buff/cache available
Mem: 3.8Gi 1.6Gi 628Mi 23Mi 1.9Gi 2.2Gi
Swap: 1.0Gi 0B 1.0Gi
在这里,不仅要看 available(可用内存)还剩多少,更要关注 Swap(交换分区) 。
如果发现 Swap 的 used(已使用)数值很大,且在配合 top 命令观察时发现系统有大量的虚拟内存换入换出活动,说明物理内存已经彻底爆满,系统不得不把速度极慢的硬盘当作临时内存使用。
如果经过这一轮排查,发现 1Panel 面板上的各项指标都处于健康状态。那么确定服务器硬件和系统环境非常健康。导致访问变慢的真凶,已经可以 100% 锁定在外部网络传输上了。
接下来,就需要移步到第二层排查,去测一测数据包的传输是否有问题。
二、排查网络延迟与连通性
如果第一步排查发现服务器内部资源充裕、负载极低,那速度慢的原因就在跨境网络传输上了。
国内用户访问海外服务器,数据包需要经过漫长的国际海底光缆,并穿过复杂的国际出口骨干网。在这个过程中,物理距离导致的延迟、晚高峰的带宽拥堵、以及糟糕的路由规划,都是导致卡顿的原因。
我们需要利用专业的网络测试工具,逐一排查以下几个核心指标。
1. 基础连通性与丢包率排查
很多人在发现网络慢时只关注 Ping 值(延迟),却忽略了另一个致命指标: 丢包率(Packet Loss) 。
对于远程管理 VPS 这种高频交互场景(如 SSH 输入命令), 高丢包率带来的痛苦远大于高延迟 。即使你的延迟只有 50ms,但如果丢包率高达 20%,可能 10 下键盘就有 2 下没有响应。
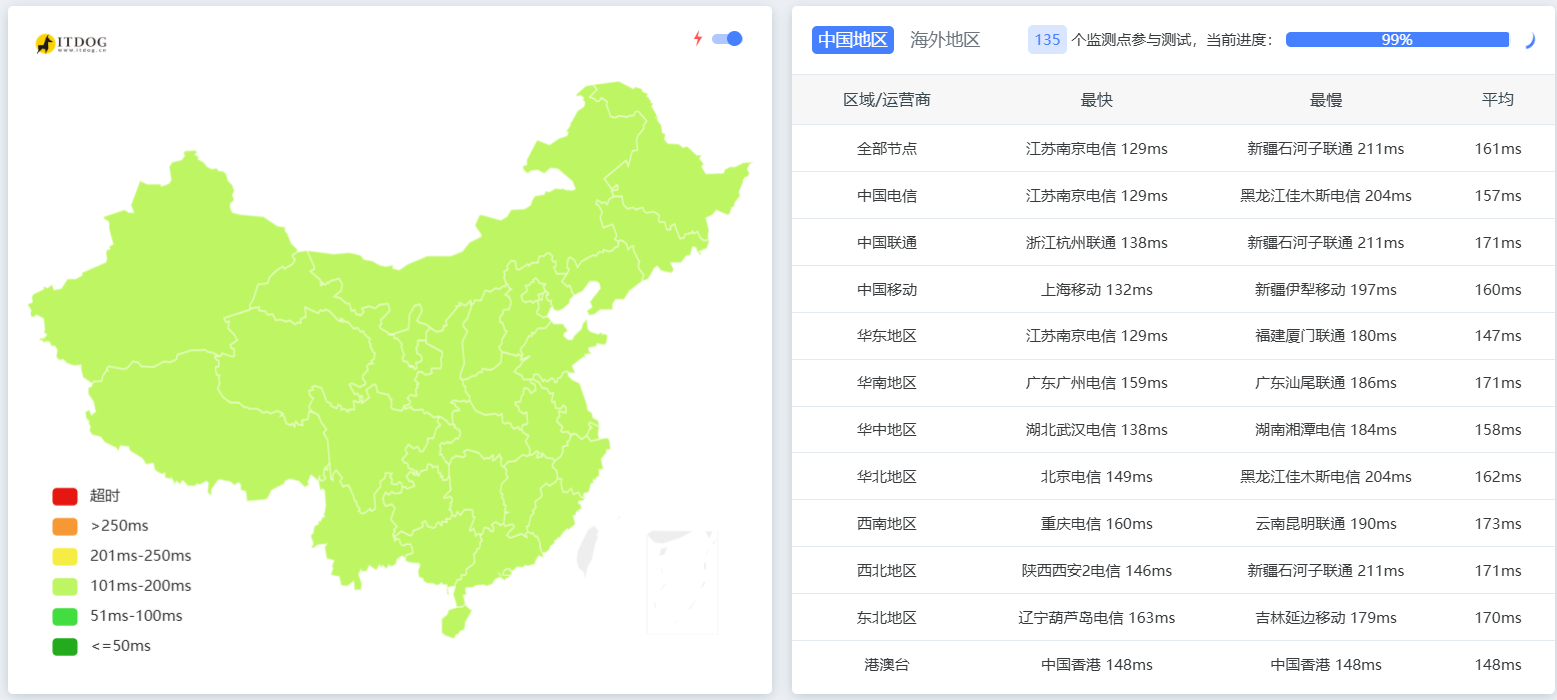
你可以通过国内的多节点 Ping 测试工具(如 ITdog)对服务器 IP 进行测试:
我是用 ping.pe 进行了丢包率测试如下:
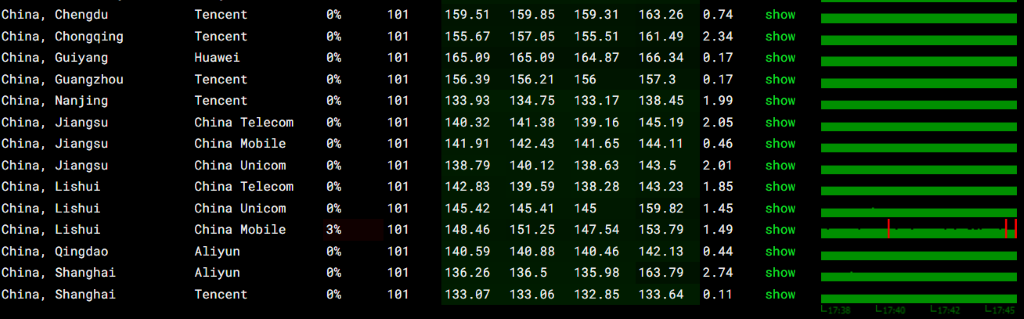
- 正常状态: 正常情况下,中国大陆访问香港 VPS 的延迟一般在 30ms - 90ms,美西(洛杉矶、旧金山)在 130ms - 190ms。更重要的是, 三网(电信、联通、移动)的丢包率应该接近 0% 。
- 异常状态: 如果发现白天网络正常,一到晚上 8 点至 11 点的晚高峰,Ping 值突然翻倍暴涨,且丢包率飙升至 10% 甚至 30% 以上,这就属于典型的国际出口骨干网拥堵造成的网络恶化。
2. 核心命脉:去程与回程路由追踪(MTR)
为什么有些商家的美西机器晚高峰依然丝滑,而你的机器却卡成 PPT?
这取决于服务器所走的是“普通公网(如电信 163 骨干网)”还是专为中国大陆优化的“精品直连线路”。在排查时,我们要借助 MTR(My Traceroute)工具查看数据包的真实轨迹。
网络路由是双向的,去程路由优秀不代表回程路由好。
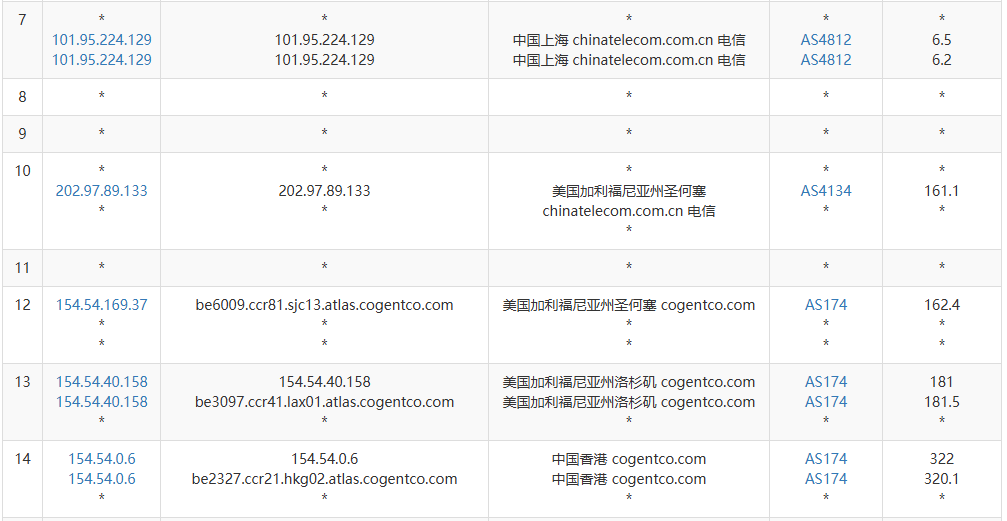
如果通过路由追踪发现,数据包不是直达。就如上面截图中:上海→美国→香港,这就说明你购买的 VPS 走的是绕路的路由,不光没有优化线路,连直连都不是所以体验极差。
3. 破局之道:认识顶级优化线路与商家推荐
面对公网晚高峰的拥堵,任何软件层面的修修补补都很难产生质的改变。最釜底抽薪的解决方案,就是直接选择接入了中国大陆顶级直连优化线路的 VPS 商家。例如:
- CN2 GIA(中国电信下一代承载网): 跨境网络中雷打不动的“高速公路”,拥有独立的国际出口链路。在晚高峰期间,当普通 163 网堵得水泄不通时,CN2 GIA 依然能够保持稳定。
- CMIN2(中国移动精品海外网): 近年来异军突起的移动顶级优化线路,在美西等地区的表现甚至不输 CN2 GIA,是移动和联通用户高性价比的极佳选择。
如果你决定给现有的卡顿环境做一次彻底的更换,以下两家专门在优化线路上深耕的商家非常值得推荐:
👑 预算充足的企业级首选:搬瓦工(BandwagonHost)
如果你对远程管理的稳定性有着近乎苛刻的要求,且用于正规的商业建站或高价值业务,搬瓦工(点击前往搬瓦工官网)是行业内标杆级的选择。
- 推荐机房: 洛杉矶 DC6 机房(机房编号:
USCA_6,全称 CN2 GIA E-Commerce )。 - 线路优势: 顶级企业级专线,同时接入了三网回程 CN2 GIA 以及最新的 CMIN2 顶级优化线路。
- 体感体验: 拥有极高的大带宽(通常 2.5Gbps 起步),全国三网全天候基本维持 0% 丢包 。晚高峰无论是 SSH 管理还是面板后台操作,体验就像连接本地局域网一样顺畅,缺点是价格相对昂贵。
💰 极致性价比的个人首选:HostDare
如果搬瓦工的价格超出了你的预算,你只是需要国内连接必须保证不卡顿、能流畅远程管理和运行小项目的服务器,HostDare(点击前往 HostDare 官网) 是一个便宜的替代方案。
- 线路优势: 其 CN2-GIA 系列回程接入 CN2 GIA + CMIN2 + CUP 线路。
- 体感体验: 虽然它的带宽上限和硬件配置相比大厂给得较为保守,但回程优化,让国内访问的延迟表现极好。关键是价格非常亲民,支持支付宝付款,非常适合预算有限的用户。
如果通过上述排查,你确信自己的网络没有绕路,却依然面临着偶尔的细微网络抖动,或者你打算在不更换现有 VPS 商家的前提下,尝试通过技术手段榨干现有网络线路的最后一点潜力。
开启 BBR 算法压榨有限的网络带宽
如果你经过前面的排查,发现现有的海外 VPS 线路在晚高峰确实存在轻微绕路或丢包,但由于种种原因(比如年付套餐没到期、迁移数据太麻烦)暂时不想更换商家,难道就只能忍受吗?
当然不是。在有限的网络条件下,我们还可以通过优化服务器底层的 TCP 拥塞控制算法,来尽可能地榨干带宽潜力,最大程度地弥补丢包带来的速度损失。
这个就是 Google 开源的 BBR (Bottleneck Bandwidth and RTT) 算法 。
为什么 BBR 能缓解丢包带来的卡顿?
传统的 Linux 默认拥塞控制算法(如 Cubic)非常保守。
一旦网络出现丢包,系统就会判定网络发生了严重拥堵,从而盲目地将发送速度直接“腰斩”切断。但在跨境网络中,很多丢包只是由于长途传输的偶发抖动导致的。
而 BBR 算法 改变了游戏规则。它通过动态测量网络的最大带宽和延迟,建立一个流量模型。即使网络出现 10% 甚至 20% 的丢包,BBR 依然能确保你的数据能够以最快速度传递过来。
对于现代主流的 Linux 系统(如 Ubuntu 20.04+、Debian 11+、CentOS 8+),其内核早已内置了 BBR 模块,我们只需要简单几行命令即可将其唤醒。
第一步:排查当前是否已开启 BBR
在终端中输入并执行以下命令,查看系统当前的拥塞控制算法:
sysctl net.ipv4.tcp_congestion_control
- 如果输出:
net.ipv4.tcp_congestion_control = bbr,说明你的服务器已经开启了 BBR,无需重复操作。 - 如果输出:
cubic或reno,说明当前的加速算法仍是传统保守模式,请继续执行第二步。
第二步:一键开启 BBR 算法
使用 root 权限或 sudo 执行以下组合命令,将 BBR 写入系统配置并使其立即生效:
# 1. 将 BBR 和 fq 队列算法写入配置文件
echo "net.core.default_qdisc=fq" >> /etc/sysctl.conf
echo "net.ipv4.tcp_congestion_control=bbr" >> /etc/sysctl.conf
# 2. 重新加载系统内核参数使其立即生效
sysctl -p
第三步:验证开启结果
再次执行验证命令,如果看到返回结果中包含了 bbr,说明网络抢救已经大功告成:
sysctl net.ipv4.tcp_congestion_control
# 正确返回应为:net.ipv4.tcp_congestion_control = bbr
此时你可以重新尝试连接 SSH 或刷新 1Panel 面板,你会发现,即便在网络环境依然恶劣的晚高峰,原本粘滞卡顿的终端也明显变得更加跟手和丝滑。
注:由于开启 BBR 涉及部分系统内核调优的细节,如果你使用的是较老版本的 CentOS 7 系统,可能还需要额外涉及升级内核的操作。不在这里展开讲解了。
总结
遇到海外 VPS 远程管理卡顿,不要上来就盲目重装系统或花钱升级硬件,按照“先内后外”的逻辑进行排查,才能精准解决问题:
- 第一步:揪出内部瓶颈(系统负载)。 利用 1Panel 面板的系统状态或终端的
top、free -h命令,确认是不是因为数据库高并发、内存爆满触发 Swap 或恶意扫盘导致服务器自己卡死。 - 第二步:排查外部网络(路由质量)。 如果机器性能富余,大概率是网络出了问题。重点关注丢包率和 回程路由 ,可以选择有优化线路的商家(预算充足上搬瓦工,追求性价比选 HostDare )。
- 第三步:软件层面抢救(开启 BBR)。 在暂时无法更换服务器的前提下,务必检查并开启系统自带的 BBR 拥塞控制算法,它能极大程度对冲跨国网络丢包带来的面板卡顿和 SSH 断连。
排查服务器就像看报告一样,看懂了系统负载和网络路由的“体检报告”,选对了拥有优质网络通道的“对口商家”,你也能拥有丝滑顺畅的海外服务器建站与管理体验。